
The challenge
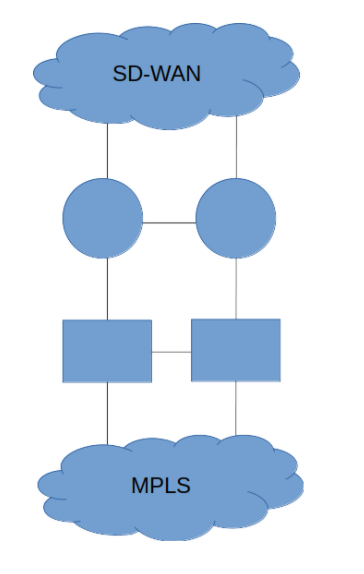
The customer where we implemented network automation, had a MPLS network with about 100 connected edge sites. Everything within this network was reachable via the MPLS network. With the migration to SD-WAN, they installed and set-up the SD-WAN core. As a next step, they wanted to migrate the edge sites to SD-WAN. Now they have two networks, MPLS and SD-WAN core, which have been connected to each other at three different locations in the world, each in a redundant setup.
To be able to migrate the edge sites to SD-WAN, several configuration changes are required for two routers and two switches at each three of these locations.
Migrating the edge sites to SD-WAN
For each site, a supernet was assigned that no longer needed to be advertised via MPLS. It needed to be redistributed from SD-WAN into MPLS on both the core routers and switches.
The configuration for the US location of the routers:
router bgp 65001
network 1.2.0.0 mask 255.255.240.0
!
ip prefix-list US-SDWAN-SUBNET permit 1.2.0.0/20
!
For the EU and APAC region, the prefix-list is different (EU or AP).
The core switch configuration for all locations is:
ip prefix-list SDWAN-TO-CORE permit 1.2.0.0/20
Implementation in NetYCE
In order to solve the above-mentioned challenges, we've used the NetYCE platform for network automation implementation. Let me first introduce three essential concepts that we use in our platform:- Inventory - for each customer we make sure that all their network inventory information is structured in one place.
- Templates - these enable you to get away from individual device commands and use smart templates to centralize all your (teams) engineering knowledge.
- Scenarios - these are basically workflows that take care of how communication in the production network should be done. Engineers can define workflows themselves so others will always use the same scenario for doing upgrades, migrations, rollbacks, etc.
- We added the core devices to the inventory of NetYCE, along with the necessary information for reachability and connectivity (IP, vendor type, credentials). Together with these mandatory variables, an additional variable is stored holding the AS number, which is different for each region.
- We used the “subnet/prefix” as an input variable along with the region of the site that is being migrated. Side note: This has to do with how the prefix-lists are used in the route-maps for primary and secondary selection with AS prepending. This part was already designed and implemented as a one-of.
- A scenario is written which includes the steps required:
- Reachability check on all devices - make sure the whole network is "up".
- Create configurations for all routers - based on the template and input variables.
- Create configurations for all switches - based on the template and input variables.
- Push the configurations.
Handling the exceptions
As usual, an exception is just around the corner! It turned out that a site doesn’t always have a single prefix. Therefore, it was necessary to be able to include more than a single prefix. The EU location also had a different setup, which doesn’t require the BGP network statement.
Put in words:The adjusted template now looks like:
|<AS>|router bgp <AS>
|<AS>| network [WordIdx(<prefix>), '/',1] mask [mask([WordIdx(<prefix>), '/',2])]
|<AS>|!
ip prefix-list [Ucase(<region>)]-SDWAN-SUBNET permit <prefix>
!
- The AS variable is only filled in the inventory where required (therefore not EU)
- The prefix variable (1.2.0.0/20) is split and a mask is calculated based on the prefix
- The region provided is forced to uppercase (to prevent input casing typo)
We updated the scenario to include an additional loop to do the same for each prefix provided:
- Reachability check on all devices - make sure either the whole network gets configured or none.
- Create configurations for all routers- based on the template, for each prefix.
- Create configurations for all switches - based on the template, for each prefix.
- Push the configurations.
Then we saved it to a job to include the reference to the scenario and the information required so we can easily reuse it.
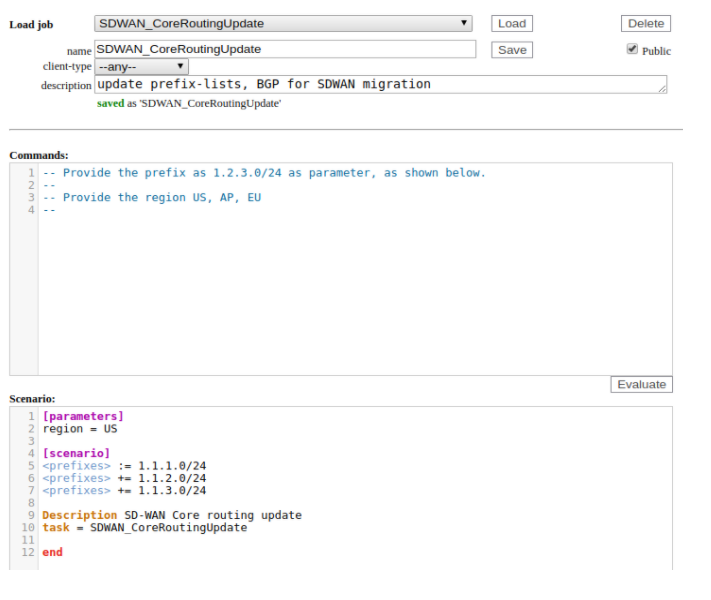
The results
The whole implementation was executed for around 200 sites. We saved a lot of time by not having to log into all devices and typing the necessary commands. But more importantly, during the process, typos were prevented by typing commands only once. There was no mix up on the location with the single prefix, no devices were forgotten, and no half-work was done.
This whole operation used to be an engineering task, but with the set-up in NetYCE this can now be delegated to operations, scheduled upfront, and linked to a change-id.

Besides the benefits of saving time and a clear implementation process without any trouble, there is more NetYCE offered:
- Backups are created pre and post-change - to view what has been changed over time and rollback if required.
- Logging is available- so it is clear who has done what and when including detailed logging of the sessions to the devices.
- Everything is available from one central GUI.
- Reports can be automatically generated - giving an overview of the migrated sites and the prefixes for these sites.
I hope this gave you more insight into how we handle these types of implementations in our platform.
